In machine learning, bias, variance, and hyperparameters are related concepts that play an important role in model performance and generalization.
Bias refers to the difference between the predicted values of a model and the true values of the data. A model with high bias tends to make consistent but incorrect predictions, while a model with low bias is able to make more accurate predictions.
Variance refers to the variability of a model's predictions for different training sets. A model with high variance is sensitive to small fluctuations in the training data and can lead to overfitting, while a model with low variance is less sensitive to the training data and can generalize better to new data.
Hyperparameters are parameters that are not learned from the data, but are set by the user prior to training a model. These can include the learning rate of a neural network, the maximum depth of a decision tree, and the regularization strength of a linear model, among others.
In Python, the scikit-learn library provides a number of tools for controlling bias, variance, and hyperparameters. For example, regularization techniques such as L1 and L2 can be used to control the variance of linear models, while the max_depth parameter can be used to control the variance of decision trees.
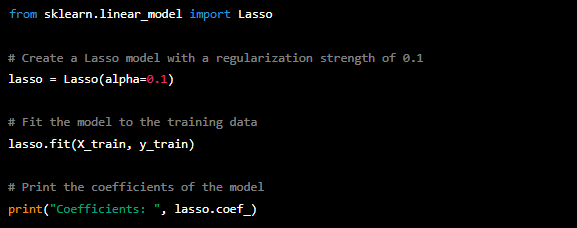
Here is an example of how to use the Lasso class to perform L1 regularization on a linear regression model:
max_depth parameter to control the variance of a decision tree:
scikit-learn library, you can use GridSearchCV and RandomizedSearchCV classes which are used to perform a search of the hyperparameters for a given model and dataset. These classes take a set of parameter ranges to search over and a scoring metric, and return the best set of parameters that maximize the scoring metric.
This code uses the GridSearchCV class to perform a grid search over the max_depth and min_samples_leaf parameters of the decision tree regressor. The cv parameter specifies the number of folds for cross-validation, and the scoring parameter specifies the metric to use for evaluating the model performance. The fit method is then called on the grid search object to train the model and search the parameter space. The best parameters and best score (i.e the best performance) are then printed.
In addition to GridSearchCV, you can also use RandomizedSearchCV class to perform a randomized search of the hyperparameters, where you specify a distribution for each hyperparameter instead of a fixed set of values. This can be useful when the search space is large and a grid search would be computationally infeasible.

In this code snippet, I've used the np.arange and np.linspace functions from the numpy library to define a range of values for the max_depth and min_samples_leaf parameters. I've also set the n_iter parameter to 10, which specifies the number of random combinations of parameters to try.
It's worth noting that you can use these functions or other similar libraries (like scipy.stats) to define distributions for the hyperparameters.
In summary, Bias-Variance tradeoff is a fundamental concept in machine learning that refers to the balance between the accuracy and generalization of a model. Hyperparameters are the parameters that are not learned from the data, but are set by the user prior to training a model. scikit-learn provides a number of tools for controlling bias, variance, and hyperparameters. GridSearchCV and RandomizedSearchCV are two of the most popular methods for hyperparameter tuning.
No comments:
Post a Comment